把样本集随机分为训练集和测试集,根据已有数据集训练一个能进行葡萄酒产地预测的模型,以正确区分三个产地所产出的葡萄酒, 分别采用PCA+Kmeans、PCA+LVQ、BP神经网络等方法进行模型的训练与测试,准确率都能达到...
”机器学习 数据集 kmeans 神经网络 算法“ 的搜索结果
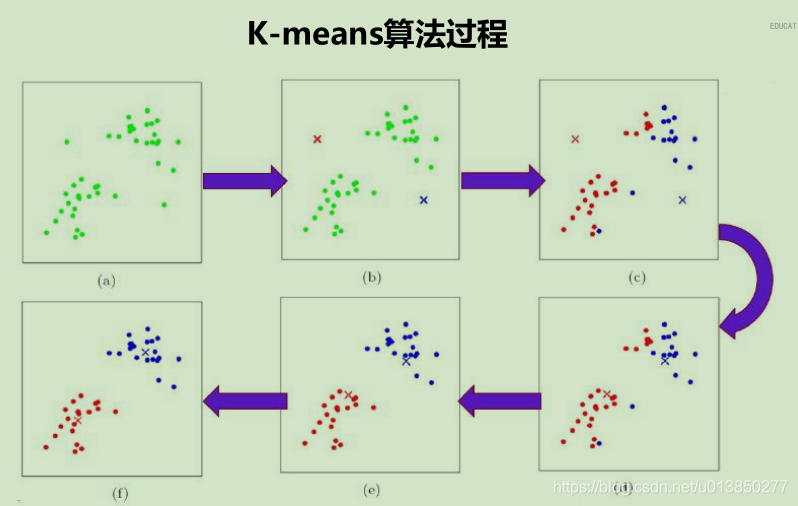
K-means算法是一种常用的聚类算法,用于将数据集划分成k个不重叠的簇。其主要思想是通过迭代的方式将样本点划分到不同的簇中,使得同一簇内的样本点相似度较高,不同簇之间的相似度较低。
1、资源内容:传入Yolo格式数据集,通过kmeans聚类得到指定数量的anchors 2、代码特点:内含运行结果,不会运行可私信,参数化编程、参数可方便更改、代码编程思路清晰、注释明细,都经过测试运行成功,功能ok的情况...



Python语言使用鸢尾花数据集实现了KNN、Kmeans、决策树、SVM、BP等十几种经典机器学习算法

本专栏内包含基于原生Python从零实现经典机器学习算法,通过自复现帮助新手小白对算法有更深刻的认识,理论与实践相结合,每一篇文章都附带有完整的代码+原理讲解。

随着科技的发展和工业界的不断创新,海量的数据已经成为当今世界的主要信息载体,而传统的基于规则的分类方法已经无法应对如此庞大的海量数据,于是人们开始寻找新的解决办法,而K-means算法正是一种非常有效的聚类...
机器学习&深度学习资料笔记&基本算法实现&资源整理.zip 0.不调库系列 No free lunch. 线性回归 - logistic回归 - 感知机 - SVM(SMO) - 神经网络 决策树 - Adaboost kNN - 朴素贝叶斯 EM - HMM - 条件随机场 kMeans ...
目标任务:使用机器学习算法对一个简单的数据集进行数据预处理。目标任务:使用监督学习算法对一个分类问题进行建模和训练。学习机器学习基础:了解机器学习的定义、分类和基本原理。每天定期复习前几天的内容,巩固...
使用著名的数据挖掘和机器学习软件WEKA,在标准数据集labor上,比较Kmeans与EM算法。


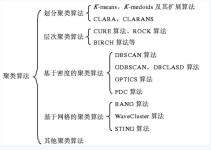
一、聚类简介是常见的unsupervised learning (无监督学习)方法,简单地说就是把相似的数据样本分到一组(簇),聚类的过程,我们并不清楚某一类是什么(通常无标签信息),需要实现的目标只是把相似的样本聚到一起,...


✅作者简介:热爱科研的Matlab仿真开发者,修心和技术同步精进,matlab项目合作可私信。????...智能优化算法 神经网络预测 雷达通信 无线传感器 ...


训练了7种机器学习算法(决策树,随机森林,逻辑回归,支持向量机,梯度提升和K最近邻和KMeans算法)和2种深度学习神经网络模型(单层感知器和多层感知器)并对其进行了测试使用电子交易数据集(kaggle)和精度最高...


基于逻辑回归和高斯贝叶斯对人口普查数据集的分类与预测
机器学习的目标是通过数据分析和模式识别来构建算法和模型,从而让计算机能够自动进行决策和预测。常见的机器学习算法包括:1.监督学习(Supervised Learning):监督学习是一种通过给定的输入和输出数据来训练模型...
推荐文章
- php 上传图片 缩略图,PHP 图片上传类 缩略图-程序员宅基地
- scrapy爬虫框架_3.6.1 scrapy 的版本-程序员宅基地
- 微信支付——统一下单——java_小程序统一下单接口-程序员宅基地
- (已解决)报错 ValueError: Tensor conversion requested dtype float32 for Tensor with dtype resource-程序员宅基地
- 记录el-table树形数据,默认展开折叠按钮失效_eltable一刷新展开的子节点展开按钮消失-程序员宅基地
- 设计模式复习-桥接模式_csdn天使也掉毛-程序员宅基地
- CodeForces - 894A-QAQ(思维)_"qaq\" is a word to denote an expression of crying-程序员宅基地
- java毕业生设计移动学习网站计算机源码+系统+mysql+调试部署+lw-程序员宅基地
- 14种神笔记方法,只需选择1招,让你的学习和工作效率提高100倍!_1秒笔记 高级-程序员宅基地
- 最新java毕业论文英文参考文献_计算机毕业论文javaweb英文文献-程序员宅基地